Unveiling IPs behind Cloudflare
Table of Contents
1 - The context
It's not that rare the need of unveiling IPs behind Cloudflare, that's a quite popular service that offers different solutions to protect your network from attacks and for load-balancing the work-load (starting from CDNs). We'll focus on the reverse proxy feature, so basically the situation which you are pointing to domain.tld and, instead of receiving data from the actual IP, you get the response from a Cloudflare's IP.
This feature works as anti-ddos as well, but we don't really need to care about it.
Even though we'll play with Cloudflare, the explained techniques will work for other services too because we'll not exploit a bug in the Cloudflare system, instead we'll exploit misconfigurations of our target (or even just bad opsec). So let's start from there.
2 - When this is expected to work, and when not
To make the whole clear and linear, let's start from the WCS (Worst Case Scenario).
Our target (domain.tld) is behind Cloudflare since the beginning of its existence, so searching for historical IPs would not work.
That's a brand new domain name, which has not been transferred (yet, at least). Plus it's using a sort of WHOIS protector (like Whois Guard). So we can't get useful results from historical WHOIS/DNS records.
The actual server, which the domain is hosted in, is properly “hard-ended” (or a minimum, at least). A couple of precautions are as follows:
- the web content is served only for the requests which have a Cloudflare's IP as origin
- connections originated from IPs which are not part of the Cloudflare's network are simply dropped
srcfields point to domains and not IPs- …
Basically, you can't reach directly what one is serving behind Cloudflare. Let it be SSH fingerprints (one of the first things which I check to de-anonymize Hidden Services), static content (favicon icons, custom JS scripts, …), whatsoever.
So a situation like this one can be really hard to defeat, thus we have some chances to retrieve the actual IP when at least one of the previous good (just my opinion here) OPSEC tips is applied.
3 - The tech-… no, the basis instead
Running tools and using lookup services can give you the awaited results, yes, but the point is that you might have wasted a lot of time and actual money to pay for the services. There's a (not so) thin difference between running tools and doing OSINT with the tools.
Bad mindset:
That tool gives this information, let's use it!
Good mindset:
I need this kind of information, let's use that tool!
So let's keep going with the “boring stuff” (once a kid said).
3.1 - Data types
Regardless the technique that you might use, there are two main categories:
- current data
- historical data
3.1.1 - Current data
It's simply what you get now, nothing more, nothing less. You'll compare that information with the historical one (gathered from any source, let's don't get deeper here).
3.1.2 - Historical data
Requirements to be classified as this:
- no more available on the domain
- provided by reliable and trustworthy sources (not something like “my friend Carl said that…", sorry Carl)
- the administrators of the target do not have the control over, anymore
The third point requires some attention: due to privacy policies, the administrators of the target might ask to “historical lookup services” to delete the records. Quite hard (I guess, I hope) but still possible.
3.2 - Data sources
3.2.1 - Browser source
By the name of this section, it should be pretty easy to understand what we're gonna play with; open your favorite browser and navigate to your target's webpage… done? OK!
Now we have to check for useful stuff; I mainly check for:
- title
- favicon
- where is the static content loaded from?
- HTML boilerplates?
- custom stuff (like screenshots, logos, and so on)
- …
So let's say that your browser made even just 50 requests (GitHub makes ~66 requests, Twitter ~127, WSJ ~213), would you check one-by-one? Really? Better filter out, saving time (= money) and patience (= mental health).
The most common causes (meaning: for what has this request been made for? To load which type of content?) are:
- document (HTML)
- img (for
<img>tags) - script (JS)
- stylesheet (CSS)
- font
- websocket* (requests)
- xhr* (requests)
- subdocument
*If you disabled the scripts with a plugin, you'll not see such requests (most probably).
We'll be back later to browser interaction related techniques.
3.2.2 - Third-party sources
Which tool or lookup service to use depends by what you are looking for, but since we don't still know what we should be looking for, I'll just name some services. Some of them are free, others paid, some could require you to login and others not. That said, there you go:
- ViewDNS.info
- CrimeFlare
- CloudFail
- DNSlytics
- RiskIQ
- Shodan
- Censys
- FavUP
- … and many many others
4 - The techniques
4.1 - Cheap Misconfigurations
I'd have named this section as Low Level Misconfigurations because of how easily we can exploit them, but I don't want to confuse you.
A misconfiguration can be considered cheap when, for example, the URL of the content(s) to load is pointing to an IP that's not part of a CDN or something that can be connected to you, like the actual IP of the server.
Q: But one could setup a server with just a CSS file and nothing else (for example), how can you say that IP is the actual IP that we are looking for?
A: Well, actually we are not looking for any true IP of the server behind Cloudflare. We are looking for information to validate, and only after that we'll make our conclusions.
Basically we are looking for IPs that are not part of CDNs et similia.
UPDATE @ Oct 20, 2019 This technique has been used against a CP sharing Hidden Service called “Welcome to Video”. Here the Son Indictment from DOJ.

4.1.1 - Browser interaction
Fire your favorite browser, open Dev Tools bar, switch to Network and keep reading here.
First thing first, let's add a couple columns to see some juicy information. I suggest you to add the Remote IP one (at least), another one that you might be interested in is Set-Cookies. Please don't confuse Set-Cookies with Cookies. The second is about what you send to the server, while the first is about what you get from the server.
You can also save some space removing columns like Timeline.
Anyway, we are still here with so many requests to filter out. What now? Instead of hiding requests by type (like all the CSS requests) which is quite out of scope, we'll filter-out by domain, which domain? The target's one! We do already know that its remote-IP is not the real one.
For example if we are visiting GitHub and we want to filter out all requests made to that domain, we can simply add -domain:github.com. Here an example of what you could get on Brave:
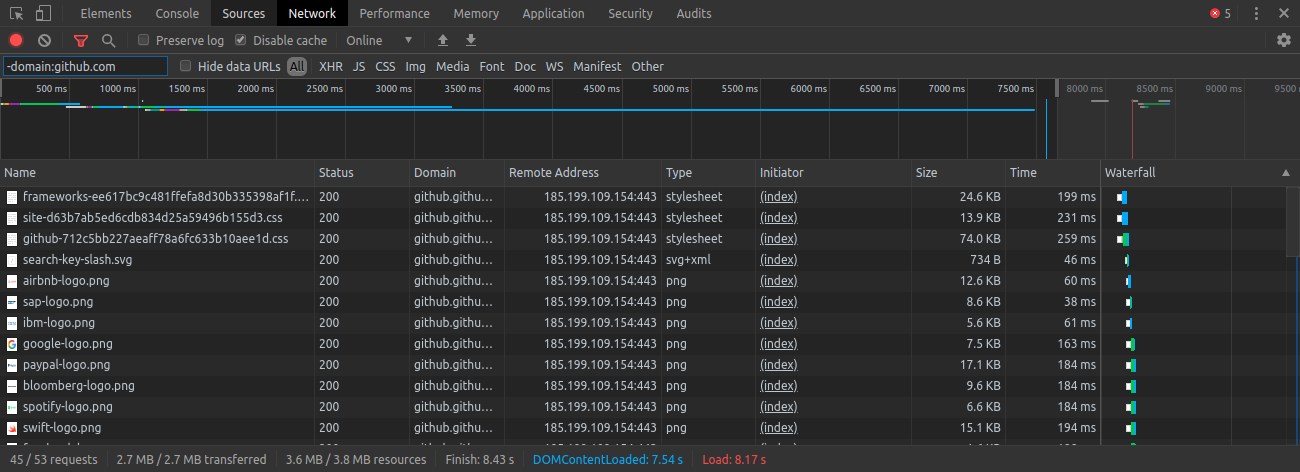
As you may see, GitHub uses various subdomains and we can exclude them all with -domain:*.github.com. If many resources are fetched from the same IP but different domains, we can exclude the IP with -remote-ip:185.199.109.154.
A full list of filter-in/out options (for Firefox) can be found here. Some filters (if not all) are similar to the ones for Chromium based web browsers.
If the filtering-out phase starts requiring a lot of time, don't freak out and keep calm. You can export all the requests made (with all the headers, the cookies, the responses, and so on) to an HAR (HTTP Archive) file (read JSON file) so that with a simple Python/GO script you will be able to do some further analysis.
To save all the requests to an HAR file, on brave, you can:
- right-click on a request and then click on “Save all as HAR with content”
- click over the “download arrow” above the tabs
On Firefox you can see the “Export to HAR” button at your right, or again right-click on a request and so on.
4.1.1 (extra) - Dealing with HAR files
Let's assume (no need in real-world cases) that we have many requests and not so much time, thus we want to automate the statistical analysis process. We have to consider as well that we have to deal with a new file type which is at least 5MB (not that much? Try opening it with a text editor).
Here's a starting-point script written in Python.
# extension is HAR, but we can read it as JSON
import json
# read the data
raw_data = open('github.har', 'r').read() # replace 'github.har' with the correct name
json_data = json.loads(raw_data) # guess what
# now the first kick on the shins
# we don't know the structure of the data
# we know that the type of the data is dict
# since all the requests are similar to the others (every request has its cookies, ...)
# we expect a list of requests as value of a key
# indeed that's what we have
for k1 in json_data:
for k2 in json_data[k1]:
if json_data[k1][k2].__class__.__name__ == 'list':
print(f"{k1} {k2} {len(json_data[k1][k2])} :: {len(json_data[k1][k2][0])}")
print('--> '+' '.join(k3 for k3 in json_data[k1][k2][0]))
# it turns out that the list with the most contents is 'entries'
requests = json_data['log']['entries']
# after exploring a few dicts/lists, you can find out that we need
# request.url, serverIPAddress and connection (port number)
ips = {}
urls = {}
ports = {}
for i in range(len(requests)):
_url = requests[i]['request']['url']
_ip = requests[i]['serverIPAddress']
_port = requests[i]['connection']
try:
ips[_ip] += 1
except KeyError:
ips.update({_ip:1})
try:
urls[_url] += 1
except KeyError:
urls.update({_url:1})
try:
ports[_port] += 1
except KeyError:
ports.update({_port:1})
for ip in ips:
print(f"{ip} :: {ips[ip]}")
for url in urls:
print(f"{url} :: {urls[url]}")
for port in ports:
print(f"{port} :: {ports[port]}")
# as you may see in the output, everything is about GitHub
# so there's no data leaking here
#
# you could try with another website, add some if/else statements
# and check wether or not all the data comes from the expected source
Maybe the example of GitHub is too boring, but now you have a simple to do a basic screening of a website in a convenient amount of time.
4.2 - Exploiting historical records
The techniques involved are pretty basic and should be considered as standards.
If the time elapsed between the creation of the domain and the implementations of shields is large enough (which in some cases can be even a single day), it could be possible to get the IP of the end point. We'll see which techniques to use when this fails.
As we've seen, shields can be applied both to WHOIS records and DNS records.
For this ViewDNS can be useful, but just for current data. For historical data you have to use a different service, and I highly suggest you RiskIQ (registration with custom email is required; GMail ProtonMail and others do not work). This service allows you to search by domain, by IP, and for almost every kind of information. It provides all records and changes of DNS/WHOIS records since the discovery of the target.
For a domain you could see who registered it and with which register, you can see all the servers’ IP which hosted that domain and many other juicy information.
An interesting feature is that it allows you to create alerts which notify you when a WHOIS record (for example) changes.
I've not had the chance, yet, to play with DNSlytics but I guess that €24/month worth it (yearly plans cost less per month). On the other side, RiskIQ community edition is pretty limited in number of searches that you can do every day.
There are many many other tools and services that you could use and there's not enough space for them all, so let's move to another technique.
4.3 - What identifies you, betrays you
I've had (and still have) a couple of targets which administrators were really meticulous… but not that much after all.
Especially one of them, it started using Cloudflare and a WHOIS “protector” since its beginning, so nothing stored in lookup services’ databases which could be used to de-anonymize them. Not a single service. So I started thinking, overthinking. Before freaking out I realized that their name is quite unique, their logos are quite unique. The name and a logo is on the webpage. So there must be a way to lookup for them.
Indeed there's.
So I thought to lookup via Shodan by favicon icon. But there was a problem, which hash is using Shodan? How does it calculate it? So I just asked around and stanley_HAL came to the rescue!
It turned out that what Shodan does, is to calculate the MMH3 hash of the encoded base64 data.
The whole was not that straight forward, I did some research on my own, asked around in different chats… so much time wasted.
So much time wasted not because I have not asked to stanley_HAL before (which is partially true), but because I realized that you can search on Shodan and Censys by HTTP title.
I'd like to underline that those two methods work only if the favicon icon and the title are unique. For example if the favicon is generated from a boilerplate and the title is “Home” it could be a though one. In such case you can filter out results by ISP, country and so on. This could be useful to fight phishing attacks.
4.4 - Other techniques
4.4.1 - Borderlines
You could apply some Social Engineering techniques to someone asking for some information. Since this could be illegal or something of doubt ethics, I'll not go further.
4.4.2 - Password recovery
If in the records there's a MX, you could use it as interesting pivot for further analysis. But sometimes you are not that lucky, and here is when password recovery comes into play. Please note that you could not be lucky here as well, sorry mate.
If this process is automated by the end-point, in the headers of the email there could be the IP address of server which was used to send that email.
If the process is not automated by the server but there are the mods dealing with you, you will basically leap in the dark.
5 - Conclusions
As OSINT teaches, there are not all-in-one solutions. One the other side, you can't know what happened in the past so using historical lookup services is almost a must.
I do hope that you understood how simple solutions (search by title) can save you time while trying to reach a result via a specific mean (favicon reverse lookup).